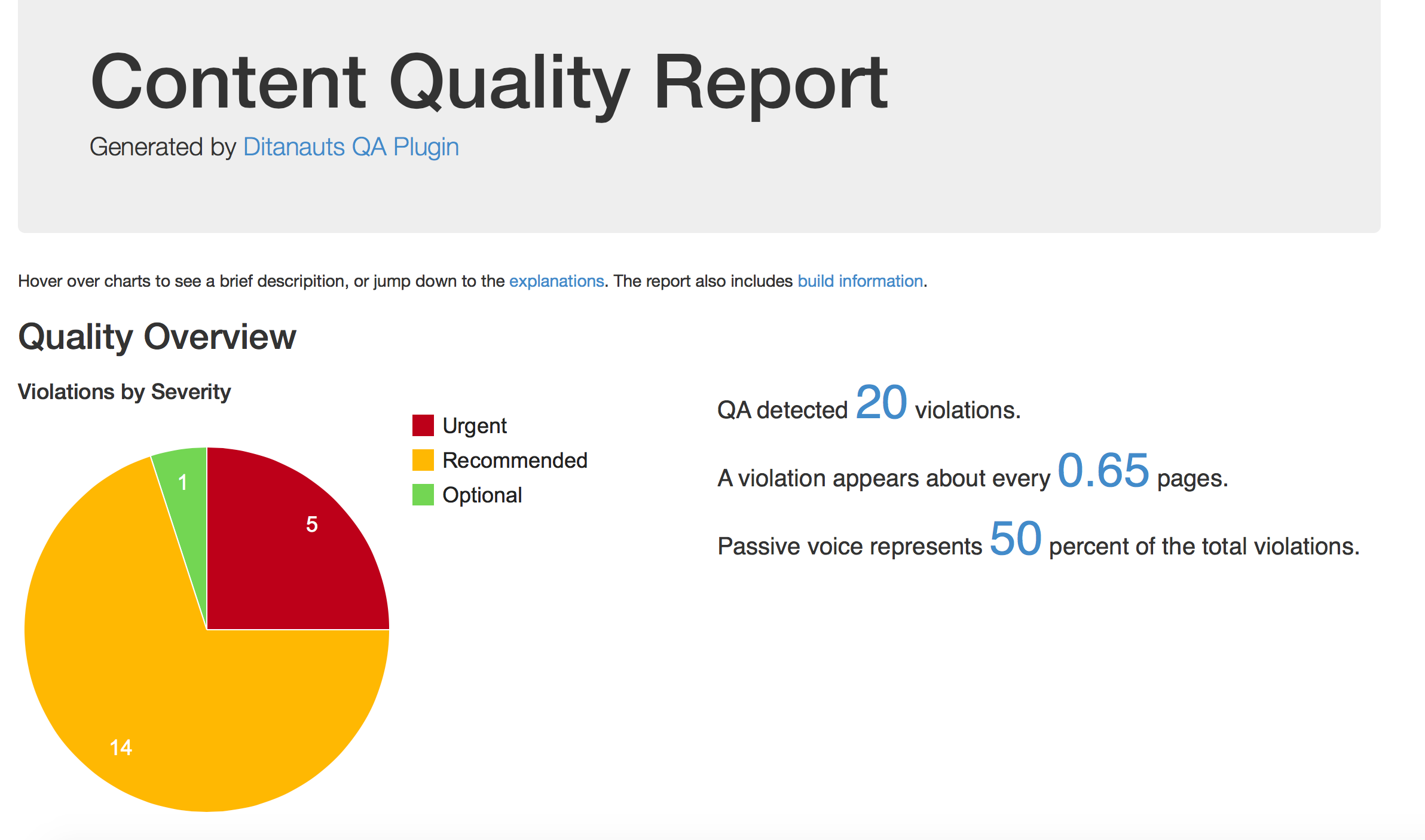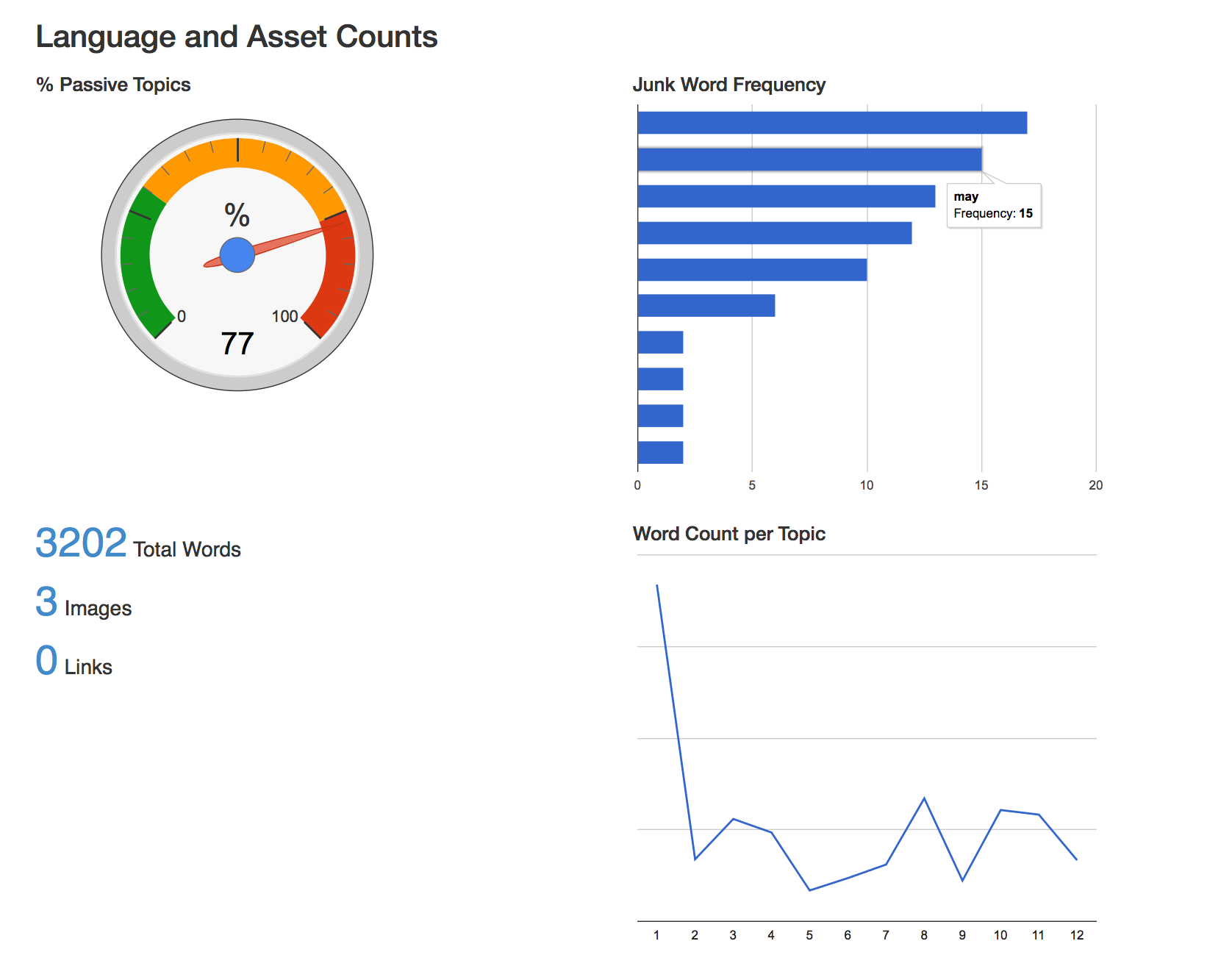
The Issue
The @chunk="to-content" requirement for the QA plugin has always been a bit sticky. Honestly, I hadn’t thought much about it since we run the QA plugin through a self-service web server and that attribute is handled by a Python controller. However, thinking in terms of local builds, it became evident that setting the @chunk by hand would quickly become a tiresome routine.
Besides attribute handling, the web server also masks another consideration—the QA plugin may not be running in isolation from other plugins.
The First Iteration
The first iteration of to move this functionality to the plugin itself resulted in a new build target extending the chunk preprocess.
In plugin.xml:
<feature extension="depend.preprocess.chunk.pre" value="setchunk"/>
The target in build_qadata.xml:
<target name="setchunk" description="Set @chunk to-content on the temp input bookmap" if="if.chunk">
<replace file="${dita.temp.dir}/${user.input.file}"
token="chunk=.to-content." value="" />
<replace file="${dita.temp.dir}/${user.input.file}"
token="<bookmap " value="<bookmap chunk='to-content' " />
<replace file="${dita.temp.dir}/${user.input.file}"
token="<map " value="<map chunk='to-content' " />
</target>
The new target used a regex replace to add the chunk attribute just before processing began in the temporary build directory. This solved the problem of manually setting the attribute, but also extended the chunk pre-processing to other sibling plugins as well.
The Solution
It’s possible to add an if-condition to a target to look for the presence of a command-line parameter, but I needed to look for a parameter with a specific value. A second iteration added a double-hop if-condition to the ant call.
<condition property="if.chunk">
<equals arg1="${setchunk}" arg2="true" casesensitive="false" />
</condition>
<target name="setchunk" description="Set @chunk to-content on the temp input bookmap" if="if.chunk">
<replace file="${dita.temp.dir}/${user.input.file}"
token="chunk=.to-content." value="" />
<replace file="${dita.temp.dir}/${user.input.file}"
token="<bookmap " value="<bookmap chunk='to-content' " />
<replace file="${dita.temp.dir}/${user.input.file}"
token="<map " value="<map chunk='to-content' " />
</target>
This approach looks for the presence of the setchunk switch and a value of true before applying the target, which is called with:
dita -f qa -i samples/taskbook.ditamap -Dsetchunk=true
So if you run the QA plugin alongside any others, you can leave off the switch to avoid unwanted chunk attributes.