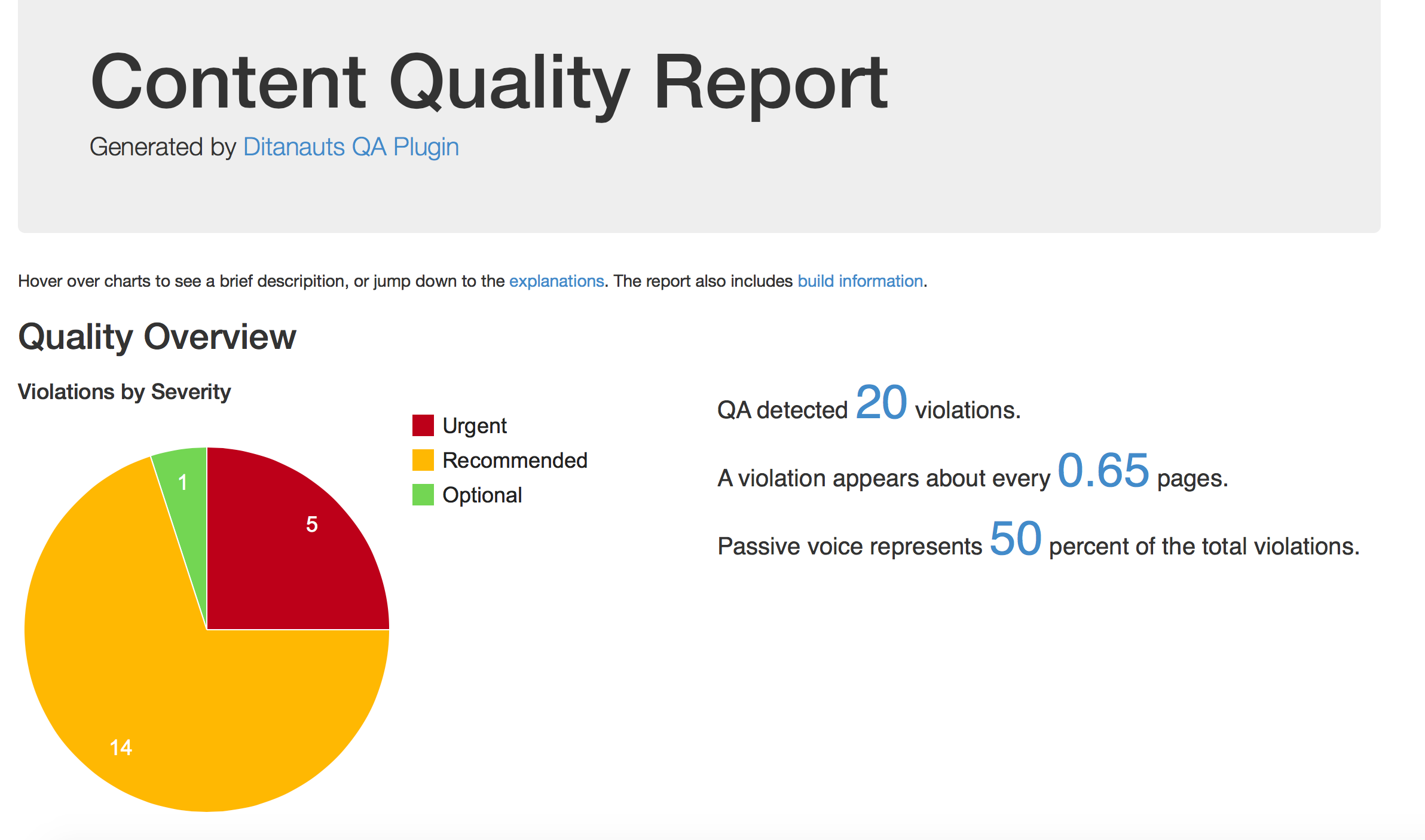
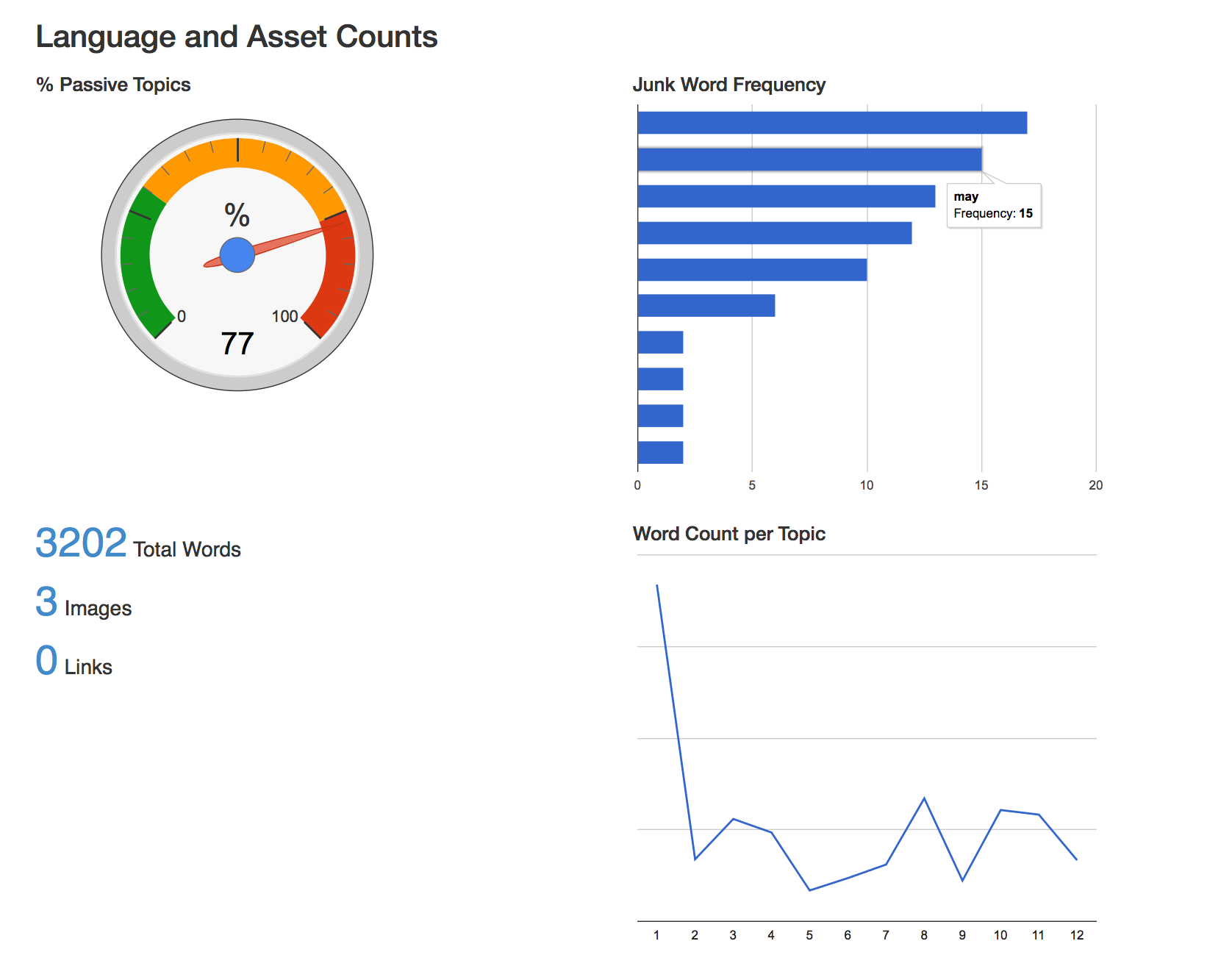
- Reports are prettier. The HTML report we generate uses Google Charts to render visual elements.
- We create a data file (written in DITA) rather than generating the report HTML directly from the DITA input. With the data file, you can then render whatever you want using normal OT processing. The plugin creates an HTML report and a .csv file from the data file.
- @Chunk set automatically on bookmaps. One of the really annoying things with the old version was that you had to set the @chunk attribute manually before a build. That is no longer the case when building from a bookmap!
I’ve updated the install and run sections of the how-to page; I will be updating the customization section soon.

Let us know what you think!
Love the improvements! But…I just noticed that the plugin automatically chunks a bookmap but not a map. Seems to me that a map would be input as frequently as as bookmap, so I was wondering why the decision not to include map in the chunk process as well? Thanks!
Thanks for the feedback Leigh. Our use case most often involved bookmap inputs, but I have added the functionality to automatically set the chunk attribute on maps as well. Hope that helps!
Here’s a strange one (with solution). When I integrated the qa plugin, it broke all my other transformations. Of all the bizarre things I’ve seen over the past 7 years working with the OT, that was a new one. The error was manifesting as the temp file not being found. I tracked the issue down to the “setchunk” target in build.xml, which is the code that adds @chunk=to-content to the map.
In that target, the temp file is specified as ${dita.temp.dir}${file.separator}${dita.input.filename}. My maps are in a subdirectory, so that location is not correct. It should be ${dita.temp.dir}${file.separator}${user.input.file}.
In addition, I found that I had to set preprocess.chunk.skip=yes for the other transformations (pdf2 and the D4P html2 and epub targets). Once I did that, the other transformations worked.
Thanks for the feedback Ben!